Capítulo 10 Proceso Control a la Divulgación Estadística (SDC) INE 2021
10.1 Introducción
Esta sección presenta el proceso SDC en una representación paso a paso y se puede utilizar como guía para el proceso SDC real, de acuerdo con los lineamientos INE 2021 (ver (Instituto Nacional de Estadísticas 2021b)). Sin embargo, debe tenerse en cuenta que, a menudo, es necesario saltar de un paso a otro y volver a los pasos anteriores durante el proceso SDC real, ya que no es necesariamente un proceso lineal paso a paso. Esta guía reúne las diferentes partes del proceso SDC como se discutió en las secciones anteriores y los enlaces a estas secciones. El estudio de caso en la siguiente sección sigue estos pasos. La Figura 10.2 al final de esta sección presenta todo el proceso de forma esquemática.
10.2 Etapa 6.4.1: Definiciones previas al proceso de anonimización
El propósito de esta etapa es establecer los requerimientos necesarios para iniciar el subproceso de control a la divulgación, que incluye la revisión de insumos, revisión de las necesidades de los usuarios y características estadísticas prioritarias, y la determinación de la necesidad de protección de confidencialidad. Esto último, está estrechamente relacionado con la interpretación de las leyes y normas sobre este tema en Chile.
Los procedimientos descritos para esta etapa aplican para todas las operaciones estadísticas y productos relacionados cuyo levantamiento de información y/o publicación sea realizado por el INE (muestras, censos, procesos de múltiples fuentes y registros estadísticos) que darán a conocer información al público general u otros usuarios. En esta etapa se debe revisar que no existan restricciones legales que impidan la publicación de los microdatos. Por otra parte, si el conjunto de datos no posee variables sensibles o variables de identificación (directa o indirecta), se pasa a la Etapa 6.4.5: Generar reportes y liberar datos.
10.2.1 Definiciones previas
Organización del proceso y equipo de trabajo: El trabajo del proceso SDC y los roles del equipo a cargo se deben organizar considerando las siguientes dos fases: diagnóstico e implementación. La fase de diagnóstico corresponde a la evaluación de riesgo de intrusión con los datos no tratados (originales o brutos), y permite juzgar si el conjunto de datos es lo suficientemente seguro para su publicación, mientras que la fase de implementación se refiere a la aplicación de métodos SDC y su evaluación, a fin de producir un conjunto de datos seguro para su publicación.
Revisión de insumos o productos estadísticos necesarios que permiten la ejecución del proceso: Se debe revisar que los insumos o productos estadísticos provenientes de los siguientes procesos en el mapa de procesos INE, segmento negocios38: 2. “Diseño y planificación”, 5. “Procesamiento” y 6.3 “Interpretar y explicar los resultados”; necesarios para la ejecución de este subproceso, se encuentren completos y actualizados. Esto incluye la revisión de convenios, fichas metodológicas, manuales de usuarios, bases de datos, diccionario de variables, paquetes estadísticos, infraestructura y seguridad, entre otros.
10.2.2 Determinación de la necesidad de protección de la confidencialidad
Antes de iniciar el proceso SDC para un conjunto de microdatos, se debe determinar la necesidad de protección de la confidencialidad. Esto está estrechamente relacionado con la interpretación de las leyes y reglamentos sobre este tema en Chile. Un primer paso es determinar las unidades estadísticas en el conjunto de datos: si se trata de individuos, hogares o entidades legales, como empresas, es probable que sea necesario controlar la divulgación. También hay ejemplos de microdatos para los que no hay necesidad de control de divulgación. Los ejemplos podrían ser datos con observaciones climáticas y meteorológicas o datos con viviendas como unidades estadísticas. Sin embargo, aunque las unidades estadísticas primarias no sean personas físicas o jurídicas, los datos pueden contener información confidencial sobre personas físicas o jurídicas. Por ejemplo, un conjunto de datos con viviendas como unidades estadísticas primarias también puede contener información sobre las personas que viven en estas viviendas y sus ingresos o un conjunto de datos sobre hospitalizaciones puede incluir información sobre los pacientes hospitalizados. En estos casos, es probable que todavía sea necesaria la protección de la confidencialidad. Una opción para resolver esto es eliminar la información sobre las personas físicas y jurídicas en los conjuntos de datos para su publicación.
Un conjunto de datos también puede contener más de un tipo de unidad estadística. El ejemplo estándar aquí es un conjunto de datos que contiene información sobre individuos y hogares. Otro ejemplo son los datos con empleados en empresas. Todos los tipos de unidades estadísticas presentes en el conjunto de datos deben ser considerados para la necesidad de SDC. Esto es especialmente importante en caso de que los datos tengan una estructura jerárquica, como individuos en hogares o empleados en empresas.
Además, se debe evaluar si las variables contenidas en el conjunto de datos son de identificación, confidenciales o sensibles. Qué variables son sensibles o confidenciales depende nuevamente de la legislación aplicable y puede diferir sustancialmente de un país a otro. En caso de que el conjunto de datos incluya variables sensibles o confidenciales, es probable que se requiera SDC. El conjunto de variables sensibles y variables de identificación junto con las unidades estadísticas en el conjunto de datos determinan la necesidad de control de divulgación estadística.
Por otra parte, se debe realizar una revisión normativa que pueda afectar o impedir la publicación de la información sujeta a anonimizar, esto incluye: identificar las restricciones actuales de publicación de la información, identificar acuerdos y restricciones de las particularidades establecidas en los convenios del INE con fuentes externas.
Si no existen variables sensibles o variables de identificación en el conjunto de datos, o restricciones desde el marco legal normativo, la decisión es pasar a la Etapa 6.4.5: Generar reportes y liberar datos, según las características establecidas en la metodología de la operación estadística o convenio institucional, según corresponda a lo establecido en el proceso 2. “Diseño y planificación”. Por el contrario, en caso de que el conjunto de datos contenga variables sensibles o variables de identificación, y no haya restricciones desde el marco legal normativo, la decisión es llevar a cabo un proceso SDC.
10.2.3 Definición de las características de las bases de datos a preservar
En este paso, analizamos los principales usos de los datos por parte de los usuarios finales del archivo de microdatos publicado. Los datos deben ser útiles para el tipo de análisis estadístico para el que se recopilaron y para el que se utilizan principalmente. Los usos y requisitos de los usuarios de datos serán diferentes para los diferentes tipos de publicación. Ponerse en contacto directamente con los usuarios de datos o buscar estudios y artículos científicos que utilicen datos similares puede resultar útil a la hora de recopilar esta información y realizar esta evaluación. Además, es importante comprender qué nivel de precisión necesitan los usuarios de datos y qué tipos de categorías se utilizan. Por ejemplo, en el caso de la recodificación global de la edad en años, uno podría recodificar la edad en grupos de 10 años, por ejemplo, \(0 – 9, 10 – 19, 20 – 29, ...\). Sin embargo, muchos indicadores relacionados con el mercado laboral usan categorías que abarcan el rango 15 – 65. Por lo tanto, construir categorías que coincidan con las categorías utilizadas para los indicadores hace que los datos sean mucho más útiles y, al mismo tiempo, reduce el riesgo de divulgación de manera similar. Este conocimiento es importante para la selección de medidas de utilidad apropiadas, que a su vez se utilizan para seleccionar los métodos SDC apropiados.
La anonimización siempre conducirá a la pérdida de información y un archivo PUF tendrá una utilidad reducida.
Las estadísticas calculadas a partir del archivo de microdatos anonimizados y publicados deberían producir resultados analíticos que concuerdan o casi concuerdan con las estadísticas publicadas previamente a partir de los datos originales. Si, por ejemplo, se calculó el promedio de ingresos de los hogares chilenos previamente a partir de estos datos y se publicó, el conjunto de datos anónimos publicado debería producir un resultado muy similar al resultado publicado oficialmente. Como mínimo, el resultado debe estar dentro de la región de confianza del resultado publicado. Puede darse el caso de que no todas las estadísticas publicadas puedan generarse a partir de los datos publicados. Si este es el caso, se debe elegir en qué indicadores y estadísticas enfocarse, e informar a los usuarios sobre cuáles se han seleccionado y por qué. Además, es importante definir porcentajes de variación permitidos por variable y niveles de desagregación geográfica o temática para las características estadísticas, a fin de medir la utilidad que compara los datos originales y los datos anonimizados, teniendo en cuenta la necesidad del usuario final para su análisis.
Algunos ejemplos de características estadísticas a preservar son las siguientes:
- Propiedades globales de las variables, como promedios.
- Mantener cifras por nivel de desagregación geográfica o temática, como, por ejemplo, mantener para la variable grupos étnicos en los totales de cada categoría a nivel regional.
- Mantener correlaciones entre variables.
- Mantener tendencias de las variables a través del tiempo, por ejemplo, si los ingresos promedio de los hogares chilenos ha presentado un comportamiento decreciente en el primer trimestre de 2021, al publicar la base de datos anonimizada el equipo de trabajo desea garantizar que esta tendencia se conserve.
Como se discutió en la Sección Medición de la utilidad y la pérdida de información, es necesario calcular medidas generales de utilidad que comparen los datos sin procesar y anonimizados, teniendo en cuenta la necesidad del usuario final para su análisis. En algunos casos, las medidas de utilidad pueden arrojar resultados contradictorios, por ejemplo, un determinado método SDC podría generar una menor pérdida de información para las cifras de la fuerza laboral pero una mayor pérdida de información para los índices relacionados con la educación. En tales casos, es posible que sea necesario clasificar los usos de los datos en orden de importancia y se debe documentar claramente para el usuario que la priorización de ciertas métricas sobre otras significa hará que algunas métricas ya no sean válidas. Esto puede ser necesario, ya que no es posible liberar varios archivos para diferentes usuarios. Este problema se presenta especialmente en estudios polivalentes. Para obtener más detalles sobre las medidas de utilidad, consulte la Sección Medición de la utilidad y la pérdida de información.
10.3 Etapa 6.4.2: Preparación y exploración de datos
Después de evaluar la necesidad de un control de divulgación estadística, debemos preparar los datos y, si hay varios, combinar y considerar todos los archivos de datos relacionados. Luego exploramos las características y la estructura de los datos, que son importantes para los usuarios de los datos. La compilación de un inventario de estas características es importante para evaluar la utilidad de los datos después de la anonimización y producir un conjunto de datos anonimizados, que es útil para los usuarios finales.
El primer paso en la preparación de datos es clasificar las variables como confidenciales o no confidenciales y eliminar identificadores directos como nombres completos, números de pasaporte, direcciones, números de teléfono y coordenadas GPS. En el caso de datos de encuestas, una inspección del cuestionario de la encuesta es útil para clasificar las variables. Además, es necesario seleccionar las variables que contienen información relevante para los usuarios finales y deben incluirse en el conjunto de datos para su publicación. En este punto, también puede ser útil eliminar variables que no sean identificadores directos del conjunto de microdatos que se publicará. Un ejemplo puede ser una variable con muchos valores faltantes, por ejemplo, una variable registrada solo para un grupo selecto de personas elegibles para un módulo de encuesta en particular y valores faltantes para el resto. Tales variables pueden causar un alto nivel de riesgo de divulgación y agregar poca información para los usuarios finales. Ejemplos son variables relacionadas con la educación (grado actual), donde un valor faltante indica que la persona no está actualmente en la escuela, o variables relacionadas con el parto, donde un valor faltante indica que la persona no ha dado a luz en el período de referencia. Los valores faltantes en sí mismos pueden ser reveladores, especialmente si indican que la variable no es aplicable. A menudo, las variables a las que les faltan la mayoría de los valores ya se eliminan en esta etapa. Otras variables que podrían eliminarse en esta etapa son aquellas demasiado sensibles para anonimizarlas y difundirlas o aquellas que no son importantes para los usuarios de datos y que podrían aumentar el riesgo de divulgación.
Las relaciones pueden existir entre las variables en un conjunto de datos por una variedad de razones. Por ejemplo, las variables pueden ser mutuamente excluyentes en los casos en que se utilizan varias variables binarias para cada categoría. Un individuo que no está en la fuerza laboral tendrá un valor faltante para el sector en el que esta persona está empleada (o, más precisamente, no aplicable). Las relaciones también pueden existir si algunas variables son proporciones, sumas u otras funciones matemáticas de otras variables. Algunos ejemplos son la variable tamaño del hogar (como un recuento de personas por hogar) o el gasto agregado (como la suma de todos los componentes del gasto). Un cierto valor en una variable también puede reducir el número de valores posibles o válidos para otra variable; por ejemplo, la edad de una persona que asiste a la educación primaria o el sexo de una persona que ha dado a luz. Estas relaciones son importantes por dos razones: 1) pueden ser utilizadas por intrusos para reconstruir valores anonimizados. Por ejemplo, si se suprime la edad pero otra variable indica que está en la escuela, aún es posible inferir un rango de edad probable para ese individuo. Otro ejemplo es si se demuestra que un individuo está activo en el Sector B de la economía. Incluso si se suprime la condición laboral de este individuo, se puede inferir que esta persona está empleada. 2) las relaciones en los datos originales deben mantenerse en el conjunto de datos anonimizados y deben evitarse las inconsistencias (por ejemplo, los métodos SDC no deben crear niños en edad escolar de 58 años o niños casados de 3 años), o el conjunto de datos será inválido para el análisis. Otro ejemplo es el caso de los gastos por categoría, donde es importante que la suma de las categorías sume el total. Una forma de garantizar esto es anonimizar los totales y luego recalcular las subcategorías de acuerdo con las acciones originales de los totales anónimos.
También es útil en esta etapa consolidar variables que brinden la misma información cuando sea posible, para reducir el número de variables, reducir la probabilidad de inconsistencias y minimizar las variables que un intruso puede usar para reconstruir los datos. Esto es especialmente cierto si los microdatos provienen de un cuestionario elaborado y cada variable representa una (sub) pregunta que conduce a un conjunto de datos con cientos de variables. Como ejemplo, tomamos una encuesta con varias variables de fuerza laboral que indican si una persona está en la fuerza laboral, empleada o desempleada, y si está empleada, en qué sector. Los datos de la Tabla 10.1 ilustra este ejemplo. Es posible que cada tipo de sector tenga su propia variable binaria. En ese caso, este conjunto de variables se puede resumir en dos variables: una variable que indica si una persona está en la fuerza laboral y otra que indica la situación laboral, así como el sector respectivo si una persona está empleada. Estas dos variables contienen toda la información contenida en las cinco variables anteriores y facilitan el proceso de anonimización. Si los usuarios de datos están acostumbrados a un determinado formato de publicación en el que la norma ha sido incluir las cinco variables, entonces es posible volver a transformar las variables después del proceso de anonimización en lugar de complicar el proceso de anonimización tratando de tratar más variables de las necesarias.
| FL-Orig | Empleado-Orig | Sector-A | Sector-B | Sector-C | FL-Nueva | Empleado-Nueva |
|---|---|---|---|---|---|---|
| Sí | Sí | NA | Sí | NA | Sí | B |
| No | No | NA | NA | NA | No | No |
| Sí | Sí | Sí | NA | NA | Sí | A |
| Sí | Sí | NA | Sí | NA | Sí | B |
| Sí | Sí | NA | NA | Sí | Sí | C |
| Sí | No | NA | NA | NA | Sí | No |
Nota sobre los pasos siguientes: Los siguientes pasos, Etapa 6.4.3: Medición y evaluación de riesgos de divulgación, Etapa 6.4.4.1: Selección y aplicación de métodos SDC y Etapa 6.4.4.2: Evaluación de proceso SDC, deben repetirse si los datos tienen identificadores indirectos que se encuentran en diferentes niveles jerárquicos, por ejemplo, individuo y hogar. En ese caso, las variables del nivel jerárquico superior deben anonimizarse primero y luego fusionarse con las variables no tratadas del nivel inferior. Posteriormente, el conjunto de datos combinado debe anonimizarse. Este enfoque garantiza la consistencia en los datos tratados. Si descuidamos este procedimiento, los valores de las variables medidas en el nivel jerárquico superior podrían recibir un tratamiento diferente para las observaciones de la misma unidad. Por ejemplo, la variable “región” es la misma para todos los miembros del hogar. Si se suprimiera el valor ‘Valparaíso’ para dos miembros pero no para los tres restantes, esto daría lugar a una divulgación no intencionada; con la identificación del hogar, la variable región sería fácil de reconstruir para los dos valores suprimidos. Las secciones Riesgo jerárquico (o del hogar) y Estructura del hogar brindan más detalles sobre cómo tratar los datos con la estructura del hogar en
RysdcMicro.
10.4 Etapa 6.4.3: Medición y evaluación de riesgos de divulgación
El propósito de esta etapa es calcular medidas de riesgo sobre los datos originales o brutos y, en base a estas medidas, juzgar si un archivo de microdatos es lo suficientemente seguro para su publicación.
Los procedimientos descritos para esta etapa aplican para todas las operaciones estadísticas y productos relacionados cuyo levantamiento de información y/o publicación sea realizado por el INE (encuestas, censos, procesos de múltiples fuentes y registros administrativos) que darán a conocer información al público general u otros usuarios.
En esta etapa solo se calculan las medidas de riesgo sobre los datos originales, que permiten decidir si el archivo de microdatos es lo suficientemente seguro para su publicación, o si requiere la aplicación de métodos SDC (ver Etapa 6.4.4.1: Selección y aplicación de métodos SDC). La decisión sobre qué hacer con las unidades riesgosas (una vez aplicados los métodos SDC) se aborda en la Etapa 6.4.4.2: Evaluación de proceso SDC.
10.4.1 Definición de escenarios de divulgación y selección de identificadores indirectos (cuasi-identificadores o variables clave)
Después de determinar el tipo de publicación de los datos, se deben examinar las posibilidades de cómo un individuo en los microdatos podría (de manera realista) ser identificado por un intruso bajo ese tipo de publicación. Para el lanzamiento de PUF, el enfoque está en el uso de conjuntos de datos externos de varias fuentes. Estas posibilidades se describen en escenarios de divulgación o intrusión, que especifican a qué datos podría tener acceso un intruso y cómo se pueden utilizar estos datos auxiliares para la divulgación de identidad. Esto conduce a la especificación de identificadores indirectos, que son un conjunto de variables que están disponibles tanto en el conjunto de datos que se publicará como en conjuntos de datos auxiliares y necesitan protección.
Esto es especialmente cierto para los lanzamientos de PUF. Los escenarios de divulgación también pueden ayudar a definir el nivel requerido de anonimización.
La redacción de escenarios de divulgación requiere el apoyo de especialistas en la materia, suponiendo que el especialista en la materia no sea la misma persona que realiza la anonimización. Los conjuntos de datos auxiliares pueden contener información sobre la identidad de las personas y permitir la divulgación de la identidad. Ejemplos de estos archivos de datos auxiliares son los registros de población y los padrones electorales, registros de Servicio de Impuestos Internos, encuestas publicadas por el INE y datos censales, así como los datos recopilados por empresas especializadas, entre otras.
De entre los diferentes escenarios de divulgación que pueden ser considerados, uno debe ser priorizado. La definición de este escenario puede responder a los siguientes criterios:
- Considerar escenarios realistas (probables). Las variables o conjuntos de datos pueden no coincidir perfectamente (por ejemplo, diferentes definiciones, variables más o menos detalladas, diferentes períodos de tiempo, etc.). Los registros externos podrían no estar lo suficientemente actualizados y, por lo tanto, un matching exacto con la base de datos a anonimizar, puede ser poco probable.
- Algunos criterios para priorizar la selección de los escenarios son: Probabilidad de datos disponibles para el intruso con más variables y categorías, y probabilidad de matching exitoso, considerando combinación de variables con mayor frecuencia.
** Notas **: - Pueden ser especificados tanto identificadores indirectos categóricos como cuantitativos. - Considerar como mínimo un identificador indirecto, pero sin número máximo. - Considerar en la definición de los escenarios, variables que den cuenta de la desagregación geográfica. Por ejemplo, región, provincia, comuna. - Considerar el escenario de reconocimiento espontáneo. Bajo este escenario, se debe verificar combinaciones raras o patrones inusuales en las variables. Ejemplos de variables que pueden conducir a reconocimiento espontáneo son: número de integrantes del hogar, área de un terreno, número de trabajadores de una empresa, ingresos y gastos, enfermedades, profesiones u oficios de baja prevalencia en el área geográfica circunscrita, entre otras. - Si el número de identificadores indirectos es alto, se recomienda reducir el conjunto de identificadores indirectos, eliminando algunas variables del conjunto de datos para su publicación. Sin embargo, esta decisión debe estar fundada bajo los siguientes criterios: 1) La variable no posee alto valor analítico y se puede prescindir de ella, o 2) La variable tiene una alta contribución al riesgo de divulgación. Si esta variable no se puede tratar adecuadamente mediante los métodos SDC (es decir, aún se mantienen altos niveles de riesgo), se debe quitar del conjunto de datos.
10.4.2 Medición y evaluación de riesgos
El siguiente paso es evaluar el riesgo de divulgación de los datos no tratados (sin procesar). Aquí es importante distinguir entre datos muestrales y datos censales. En el caso de los datos del censo, es posible calcular directamente las medidas de riesgo cuando se supone que el conjunto de datos cubre a toda la población. Si se trabaja con una muestra, o una muestra del censo (que es el caso más común cuando se liberan datos de muestra), podemos usar los modelos discutidos en la Sección Medición de riesgos para estimar el riesgo en la población. Las principales entradas para la medición del riesgo son el conjunto de identificadores indirectos determinados a partir de los escenarios de divulgación en la sección anterior y los umbrales para los cálculos de riesgo (por ejemplo, el nivel de k-anonimato o el umbral por el cual un individuo se considera en riesgo). Si los datos tienen una estructura jerárquica (por ejemplo, una estructura de hogar), el riesgo debe medirse teniendo en cuenta esta estructura como se describe en la Sección Riesgo jerárquico (o del hogar).
Cada una de las diferentes medidas de riesgo descritas en la Sección Medición de riesgos tiene ventajas y desventajas. En general, el k-anonimato, el riesgo individual y el riesgo global se utilizan para producir una idea del riesgo de divulgación. Estos valores pueden ser inicialmente muy altos, pero a menudo pueden reducirse muy fácilmente después de una recodificación simple pero apropiada (consulte la Etapa 6.4.4.1: Selección y aplicación de métodos SDC). Los umbrales son los establecidos por la institución de acuerdo con el tipo de operación estadística. Recuerde siempre, sin embargo, que al usar una muestra, las medidas de riesgo basadas en los modelos presentados en la literatura ofrecen el peor escenario de riesgo y, por lo tanto, podrían ser una exageración de los riesgos reales para algunos casos (consulte la Sección Riesgo individual).
10.5 Etapa 6.4.4.1: Selección y aplicación de métodos SDC
La selección de los métodos SDC depende de la necesidad de protección de datos (medida por el riesgo de divulgación), la estructura de los datos y el tipo de variables. La influencia de los diferentes métodos sobre las características de los datos importantes para los usuarios o la utilidad de los datos también debe tenerse en cuenta al seleccionar los métodos SDC. En la práctica, la elección de los métodos SDC es parcialmente un proceso de prueba y error: después de aplicar un método elegido, el riesgo de divulgación y la utilidad de los datos se miden y comparan con otras opciones de métodos y parámetros. La elección de los métodos está sujeta a la legislación, por un lado, y a un compromiso entre utilidad y riesgo, por el otro.
La clasificación de métodos que se presenta en la Tabla 10.2 ofrece una buena visión general para elegir los métodos apropiados. Los métodos deben elegirse según el tipo de variable, continua o categórica, los requisitos de los usuarios y el tipo de liberación. Para una descripción más completa de estos métodos, consulte la Sección Métodos SDC.
| Método | Clasificación | Tipo de datos | Función en sdcMicro |
|---|---|---|---|
| Recodificación global | No perturbativo, determinístico | Continuo y categórico |
globalRecode,groupVars
|
| Codificación superior e inferior | No perturbativo, determinístico | Continuo y categórico |
topBotCoding
|
| Supresión local | No perturbativo, determinístico | Categórico |
localSuppression,localSupp
|
| PRAM | Perturbativo, probabilístico | Categórico |
pram
|
| Microagregación | Perturbativo, probabilístico | Continuo |
microaggregation
|
| Adición de ruido | Perturbativo, probabilístico | Continuo |
addNoise
|
| Barajado | Perturbativo, probabilístico | Continuo |
shuffle
|
| Intercambio de rango | Perturbativo, probabilístico | Continuo |
rankSwap
|
En general, para la anonimización de variables categóricas, es útil restringir el número de supresiones aplicando primero una recodificación global y/o eliminando variables del conjunto de microdatos. Cuando el número requerido de supresiones para lograr el nivel de riesgo requerido es suficientemente bajo, las pocas unidades en riesgo pueden ser tratadas mediante supresión. Estos son generalmente valores atípicos. Cabe señalar que posiblemente no todas las variables se puedan publicar y algunas se deban eliminar del conjunto de datos (consulte la Etapa 6.4.2: Preparación y exploración de datos). La recodificación y el uso mínimo de la supresión garantizan que las cifras ya publicadas de los datos sin procesar se puedan reproducir suficientemente bien a partir de los datos anonimizados. Si se aplica la supresión sin una recodificación suficiente, el número de supresiones puede ser muy alto y la estructura de los datos puede cambiar significativamente. Esto se debe a que la supresión afecta principalmente a las combinaciones que son raras en los datos.
Si los resultados de la recodificación y la supresión no logran el resultado requerido, especialmente en los casos en que el número de identificadores indirectos seleccionados es alto, una alternativa es usar métodos perturbativos. Estos se pueden utilizar sin una recodificación previa de las variables. Estos métodos, sin embargo, preservan la estructura de datos solo parcialmente. El método preferido depende de los requisitos de los usuarios. Nos referimos a la Sección Métodos SDC y especialmente a la Sección Métodos perturbativos para una discusión de los métodos perturbativos implementados en sdcMicro.
Finalmente, la selección de los métodos SDC depende de los datos utilizados, ya que los mismos métodos producen diferentes resultados en diferentes conjuntos de datos. Por lo tanto, la comparación de resultados con respecto al riesgo y la utilidad (ver Etapa 6.4.4.2: Evaluación de proceso SDC) es clave para la elección realizada. La mayoría de los métodos se implementan en el paquete sdcMicro. Sin embargo, a veces es útil emplear soluciones a medida. En la sección Métodos SDC se presentan algunos ejemplos.
10.6 Etapa 6.4.4.2: Evaluación de proceso SDC
El propósito de esta etapa es verificar si la base de datos anonimizada cumple con las condiciones para presentarse como versión final. Estas son: el nivel de riesgo definido en la Etapa 6.4.3: Medición y evaluación de riesgos de divulgación y la utilidad esperada definida en la Etapa 6.4.1: Definiciones previas al proceso de anonimización.
Su alcance considera la reevaluación del riesgo y la medición de la utilidad, comparar con mediciones de los datos originales y decidir si la base cumple o no con los criterios establecidos.
10.6.1 Vuelva a medir el riesgo
En este paso, reevaluamos el riesgo de divulgación con las medidas de riesgo elegidas en la Etapa 6.4.3: Medición y evaluación de riesgos de divulgación después de aplicar los métodos SDC. Además de estas medidas de riesgo, también es importante observar a las unidades con alto riesgo y/o características especiales, combinaciones de valores o valores atípicos en los datos. Si el riesgo no está en un nivel aceptable, la Etapa 6.4.3: Medición y evaluación de riesgos de divulgación y Etapa 6.4.4.1: Selección y aplicación de métodos SDC deben repetirse con diferentes métodos y/o parámetros.
Medidas de riesgo basadas en conteos de frecuencia (k-anonimato, riesgo individual, riesgo global y riesgo del hogar) no se pueden utilizar después de aplicar métodos perturbativos ya que sus estimaciones de riesgo no son válidas. Estos métodos se basan en introducir incertidumbre en el conjunto de datos y no en aumentar las frecuencias de las claves en los datos y, por lo tanto, sobreestimarán el riesgo.
10.6.2 Mida la utilidad
En este paso, volvemos a medir las medidas de utilidad definidas en la Etapa 6.4.1: Definiciones previas al proceso de anonimización y las comparamos con los resultados de los datos sin procesar. Además, aquí es útil construir intervalos de confianza alrededor de las estimaciones puntuales y comparar estos intervalos de confianza. La importancia del valor absoluto de una desviación solo puede interpretarse conociendo la varianza de la estimación. Además de estas medidas de utilidad específicas, se deben evaluar las medidas de utilidad general, como se analiza en la Sección Medición de la utilidad y la pérdida de información. Esto es especialmente importante si se han aplicado métodos perturbativos. Si los datos no cumplen con los requisitos del usuario y las desviaciones son demasiado grandes, repita la Etapa 6.4.3: Medición y evaluación de riesgos de divulgación y Etapa 6.4.4.1: Selección y aplicación de métodos SDC con diferentes métodos y/o diferentes parámetros.
La anonimización siempre conducirá a al menos alguna pérdida de información.
10.6.3 Evaluación de reglas de validación y consistencia
Por último, se debe verificar que todas las relaciones en los datos anonimizados preserven todas las reglas de validación y consistencia propias de la operación estadística. Esto incluye:
- Variables que son sumas de otras variables o proporciones.
- Relaciones de orden, por ejemplo, la variable X debe ser siempre menor a la variable Y.
- Cualquier valor inusual causado por la anonimización debe ser detectado. Por ejemplo, los ingresos negativos, una persona de 14 años en la fuerza laboral o un alumno en el vigésimo grado de la escuela. Esto puede suceder después de aplicar métodos perturbativos de SDC.
Se debe verificar que los indicadores publicados previamente de los datos originales o brutos son reproducibles a partir de los datos que se van a publicar. Si este no es el caso, los usuarios de datos podrían cuestionar la credibilidad del conjunto de datos anonimizados.
En la Figura 10.1 se presenta el flujo que resume las actividades que componen esta etapa y que, en consecuencia, permite juzgar la efectividad de los métodos SDC aplicados y la factibilidad de liberar el conjunto de microdatos.
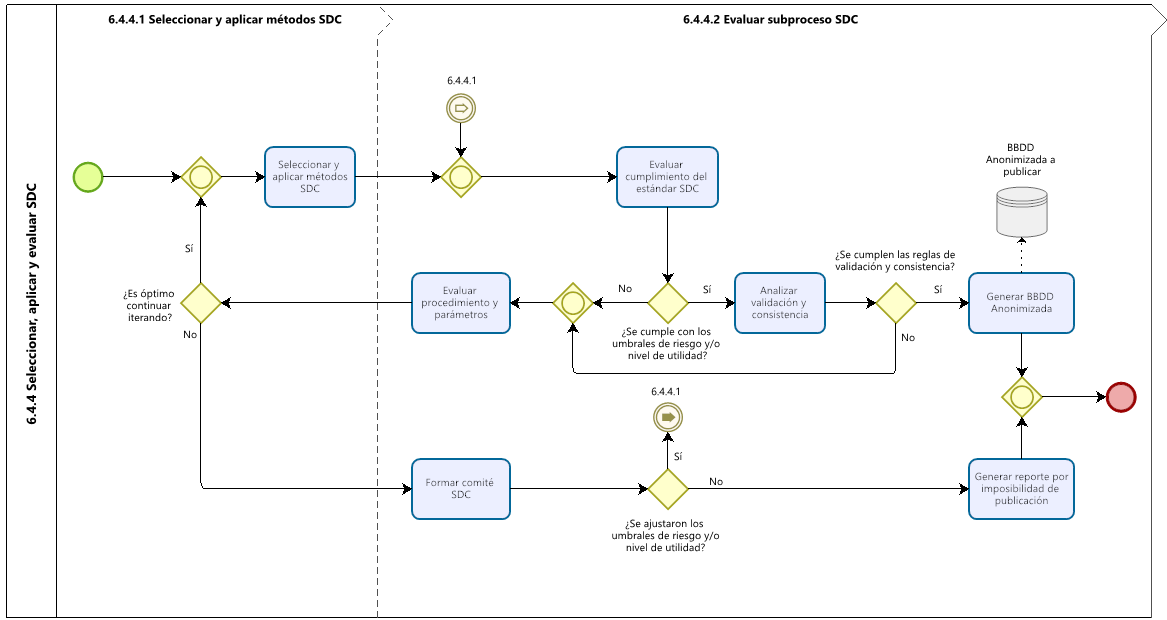
Figura 10.1: Evaluación de proceso SDC INE 2021.
10.7 Etapa 6.4.5: Generar reportes y liberar datos
El propósito de esta etapa es la generación de reportes, tanto interno como externo, que acompañan la liberación de datos.
Los informes internos contienen la descripción exacta de los métodos de anonimización utilizados, los parámetros, pero también las medidas de riesgo antes y después de la anonimización. Esto permite la replicación del conjunto de datos anonimizados y es importante para las autoridades/organismos de control para garantizar que el proceso de anonimización sea suficiente para garantizar el anonimato de acuerdo con la legislación aplicable.
Los informes externos informan al usuario que los datos han sido anonimizados, brindan información para un análisis válido de los datos y explican las limitaciones de los datos como resultado de la anonimización. Puede incluirse una breve descripción de los métodos utilizados. La publicación de microdatos anonimizados debe ir acompañada de los metadatos habituales de la encuesta (peso de la encuesta, estratos, metodología de la encuesta), así como información sobre los métodos de anonimización que permiten a los investigadores realizar análisis válidos (por ejemplo, cantidad de ruido agregado, matriz de transición para PRAM).Se debe tener cuidado de que esta información no se pueda utilizar para la reidentificación (por ejemplo, no se libera semilla aleatoria para PRAM).
Por otra parte, los metadatos deben actualizarse para cumplir con los datos anonimizados. Las descripciones de las variables o las etiquetas de valores pueden haber cambiado como resultado del proceso de anonimización. Además, la pérdida de información debido al proceso de anonimización debe explicarse en detalle a los usuarios para que sean conscientes de los límites de la validez de los datos y sus análisis.
El último paso en el proceso de SDC es la publicación real de los datos anónimos. En el contexto INE, el tipo de publicación factible es el PUF. Los cambios realizados en las variables en la Etapa 6.4.2: Preparación y exploración de datos, como la fusión de variables, se pueden deshacer para generar un conjunto de datos útil para los usuarios.
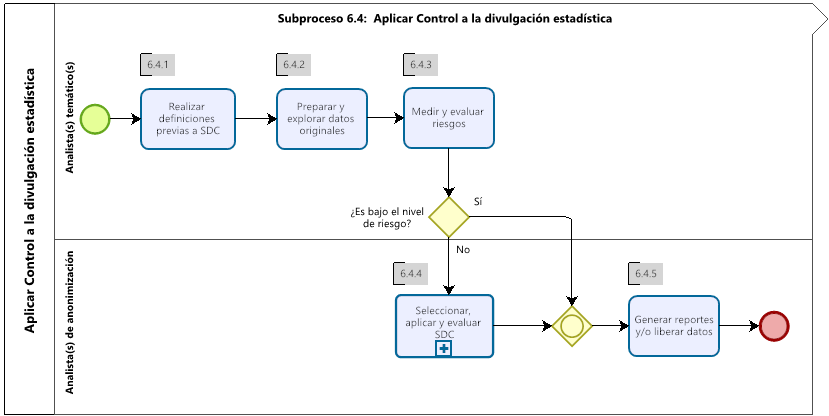
Figura 10.2: Esquema general de proceso SDC INE 2021.